Words, words, words!
Originally published on Mon, 01/06/2014 - 02:17
For quite some time I have been thinking about writing a blog entry about lexical issues. Computational lexicons are things that I have been wrestling with for many years. Not only are there new terms (lexemes, abbreviations, emoticons, etc.) that are “listemes” – meaning that they can be found in dictionaries (even emergent ones like the urban dictionary) but English is amazingly productive in many ways. There will always be terms in texts that have not and cannot be enumerated. For example, if I say something is “doubtable” you certainly would know what I mean even if you could not find it in a dictionary.
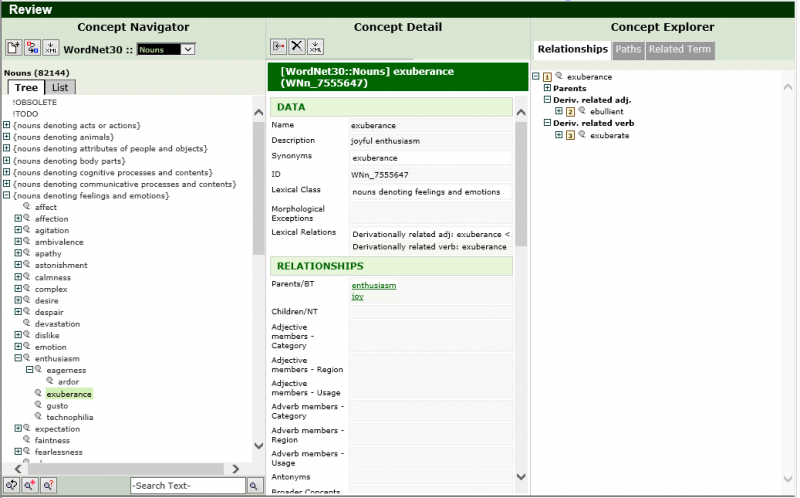
Arity, my previous company, created an application for the editing and maintenance of lexicons. Below is a screen grab of WordNet http://wordnet.princeton.edu/, a large lexicon of English running in Arity’s LexiLink. Headspace Sprockets has developed a successor to LexiLink.
I have used many resources in addition to WordNet, and have derived new lexical resources using textual analysis techniques.
Large-scale deep computational linguistics requires very sophisticated lexical-semantic machinery. I work in a discipline called “Sign Based Construction Grammar” (SBCG) which is a variant of “Head-driven Phrase Structure Grammar” (HPSG). SBCG is highly lexicalized, meaning that the location of most of the linguistic knowledge that is used during parsing and generation is derived from the structures that are associated with the words and tokens found in the textual source or generated surface forms. Some of the structures associated with words can be more or less directly looked up from pre-indexed and pre-computed lexicons but most of the time words or tokens require pre-processing. The sorts of pre-processing that I have been addressing include:
• More or less direct association of structures to function words and tokens – those listemes that do not belong to the open classes of nouns, verbs, adjectives, and adverbs – which change very slowly in a language. Even function words have much complexity and often have different senses and contextual uses that require different structures.
• Regular inflection rules – amazingly complex rules for adapting a lexeme to the appropriate form based on case – where some rules are based on Greco-Latin inflection, some on Romance, and some are core to English.
• Irregular morphology – words that inflect outside of any fixed rules (see, saw, seeing, seen).
• Derivation rules that use affixes to change the meaning of a word (and possibly its part of speech) (teach, teacher) where some of the productivity may be based on predictable semantics (“anti-“ usually means “against”) but most affixes have multiple meanings. The generative choice of which affix to apply to change the meaning of a word has some regularity but often seems arbitrary. There is a large and vibrant literature that addresses the (semi-) regularity evident in derivational morphology.
• Compounding where multiple words are juxtaposed to make a new word (“double-digit”) where one of the words (usually the one on the right) is a base type that is modified by the other word (the new word is a hyponym of one of the elements). These are called “endocentric compounds”.
• Exocentric compounds where multiple words are used but neither component word is a base type (“redhead” where neither “red” nor “head” is a person, but rather obliquely the attributes of the base type (person) is being used to distinguish a derived type.
• Punctuation and a host of tokens including tokens that may be recognized as forming a proper name, a date, a currency, an email address, or any one of many noun types.
All of this is further muddied by words typically having more than one sense. Even function words can have more than one sense. For example, “we” generally means a close and intimate group including the speaker (“we are going on vacation”). But “we” as used by a politician can mean any of “me”, “those who agree with me”, “everyone in America”, “everyone in my party”, etc.
Even worse are covert uses of multi-word expressions. For example, there is an anatomical structure called “gastric mucosa” which is one of several kinds of mucosae found in the human body. I can write: “The stomach has 5 layers. The mucosa is the innermost layer.” In this case the multi-word expression has a part (“gastric”) that is suppressed but inferable from context.
And yet even worse is the problem of vagueness – saying that I saw a “big mouse” means that it is big for a mouse but certainly not even a “big animal”. And think of the word “pretty” used as a modifier. If I say something is “pretty cold”, I mean that it is cold. But if I say something is “pretty straight”, I mean that it is not straight (but not too far off).
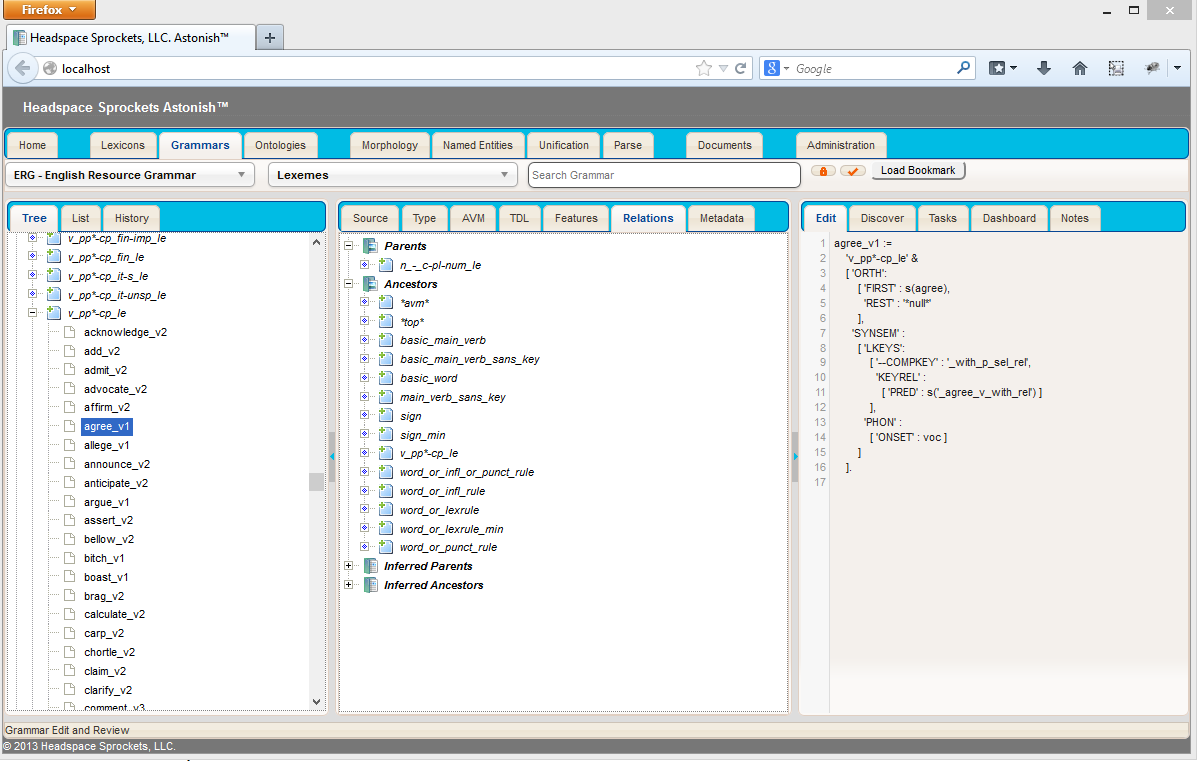
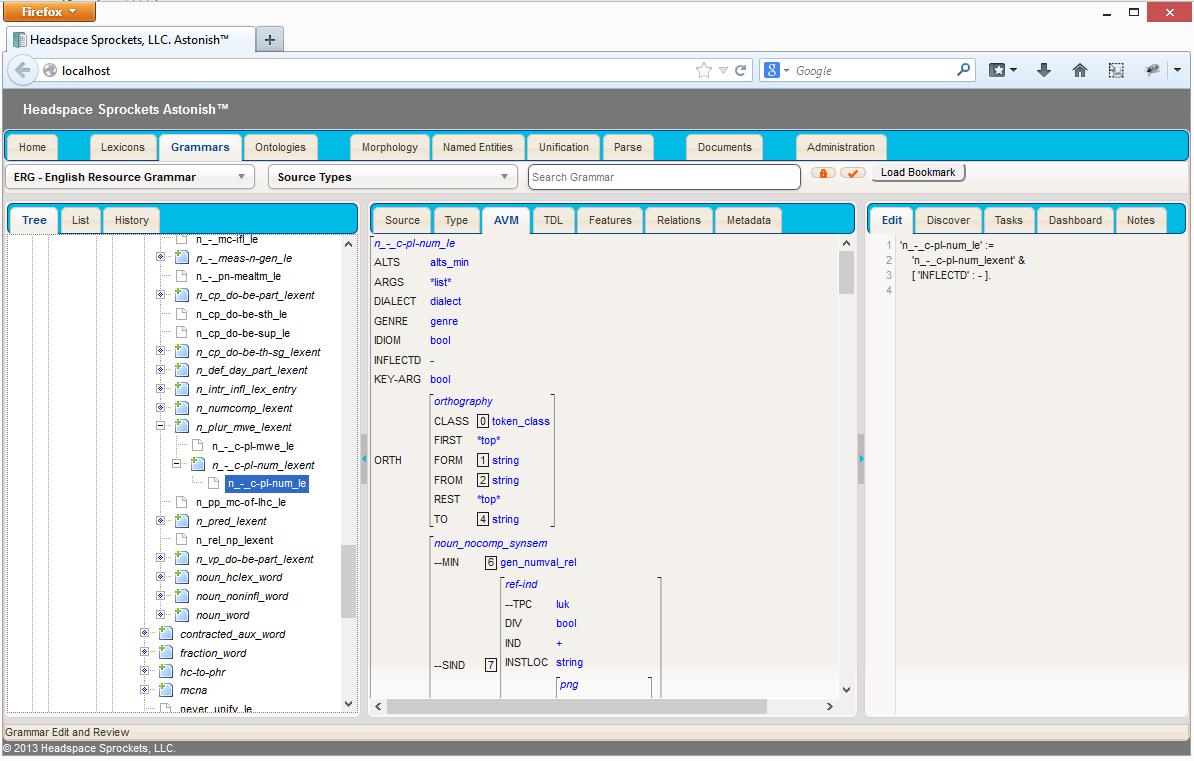
The literature on these phenomena is immense and many controversies remain. I am interested in creating useful systems and time is limited so often I need to leave behind some really fascinating discussions to get actual work done. Headspace Sprockets currently uses some rather large lexicons (WordNet, VerbNet, ERG, FrameNet, MeSH, and others) plus a whole lot of rules in a lexical/syntactic/semantic inference system. It’s all pretty massive. I sometimes use the English Resource Grammar (ERG) in a modified form for testing and insights. Below are some screenshots of one of our linguistic technology development tools showing one of the senses of the verb “agree”.