Recommended Resources for AI, Machine Learning and Big Data
This is a personal list of basic references that I believe are among the best to initially dive into an area; These have been and will continue to be updated from time to time. I have added some comments that should be taken with a few grains of salt. I did not include references to research papers or some of the deeper literature - I can provide you with some recommendations if you have some particular directions that you want to push in. In a small number of cases, I have used some of the materials below as the basis for some teaching that I have done.
I have not included any of the rather large number of casual introductions that provide icing but no cake. I usually find that surveys that are light weight are either biased or leave some erroneous impressions.
The Semantic Web community seems to me to under emphasize the primacy of machine learning, inference, and practical aspects of knowledge management. So, my ordering of subjects for discussion is intentionally contrary.
Deep Learning
There is one must-have book:
Ian Goodfellow, Yoshua Bengio and Aaron Courville
Deep Learning (Adaptive Computation and Machine Learning series)
(The MIT Press, 2016)
https://www.amazon.com/Deep-Learning-Adaptive-Computation-Machine/dp/0262035618This book is excellent and rightly is a source that is cited by essentially everyone publishing work on deep learning subsequent to its publication. The introductory chapters (1 through 5) provide only a minimal background necessary for the rest of the book so I advise getting a firmer foundation by reading some of the materials listed in the next section.
For an intriguing exploration into the unreasonable effectiveness of deep learning there is a excellent short paper that provides a view from a physics perspective:
Henry W. Lin, Max Tegmark, David Rolnick
Why does deep and cheap learning work so well?
https://arxiv.org/abs/1608.08225
Hundreds of papers are published each year advancing the state-of-the-art of deep learning and applying those advances to different application areas. The largest open questions are how to gauge and improve the robustness of learning and how to understand exactly what is being learned during training.
General Background on Pattern Recognition and Machine Learning
The following books are excellent introductions to pattern recognition technology and algorithms. This includes density estimation, clustering, classification, regression, and summarization methods. Some less rigorously motivated data mining techniques (such as association rule induction) are not covered in these references.
R. O. Duda, P. E. Hart and D. G. Stork
Pattern Classification (2nd Edition)
(John Wiley & Sons, 2001)
https://www.wiley.com/en-us/Pattern+Classification%2C+2nd+Edition-p-9780471056690The first edition is a classic! This second edition narrows its scope but deepens and strengthens its presentation. Many wonderful insights and algorithms are presented well. Early printings were riddled with typos, but can be fixed using a list available on the Web. Also, it should be regarded as a survey, not as a definitive source. In this light it is excellent as a general introduction.
I taught a portion of a course that was using this book - my lecture focus was on the ways that models can be tested and validated. I thought that the book did a good job of preparing the students (who were engineers and mathematicians at MITRE Corporation).
T. Hastie, R. Tibshirani and J. H. Friedman
The Elements of Statistical Learning - Data Mining, Inference, and Prediction 2nd Edition
Springer Series in Statistics, 2016
https://www.amazon.com/Elements-Statistical-Learning-Prediction-Statistics/dp/0387848576/This is an excellent book on data mining based on a very statistical perspective. Probably the best single introductory book on data analysis at a reasonably advanced level.
Gilbert Strang
Linear Algebra and Learning from Data
(Wellesley-Cambridge Press, 2019)
https://www.amazon.com/Linear-Algebra-Learning-Gilbert-Strang/dp/0692196382This is the book to read after you have learned a bit about linear algebra so you can really know what it is all about. One of my regrets looking back at my time at MIT is that I did not take a course from Professor Strang. Fortunately, his lectures are available on-line. Linear algebra is so fundamental to all machine learning that perhaps I should have placed this book recommendation before all others.
C. M. Bishop
Pattern Recognition and Machine Learning
(Springer, 2007)
https://www.amazon.com/gp/product/1493938436I loved Bishop's 1995 Neural Networks for Pattern Recognition and this successor is excellent.
Statistical Learning Theory and Kernel Methods
Kernel methods are based on the observation that many machine learning algorithms are, or can be generalized using a "trick." This generalization takes a linear algorithm (such as simple classification or regression) and re-casts the underlying mathematics so that the representation of the calculations uses dot products (as in vector dot products.) A kernel is a function that effectively computes a dot product in some transformed space. So, if you had two vectors, X and Y, you would compute the dot product in Cartesian coordinates by multiplying their corresponding components and summing.
Now, if you have some (non-linear) function, say $F(x)$, you could take a dot product in that space. Why would you want to do this? Because the pattern that you are trying to uncover might be easier to discover and analyze if transformed into a linear space. This is just analogous to all kinds of transforms that change a problem - such as Fourier transforms allow analysis in the frequency domain instead of the time domain.
So what is the problem? Well, computing $F(x)$ for the data might be HORRIBLY inefficient or hard. There are many reasons why this may be so. But for many functions we can find another function which is relatively easy to compute called a "kernel" -
We compute $k(X, Y)$ in some direct way that is equivalent to the above, but is much easier. We substitute its use wherever we have the dot product in a linear algorithm and by magic we have a non-linear more general algorithm.
Many of the interesting developments in machine learning in the last two decades or so have been based on this trick and on new, deeper insights into the fundamental trade-offs while learning.
And speaking of trade-offs, the main trade-off in learning has to do with specialization / generalization. Do we learn a function that fits a training set of data so well that it follows every nook and cranny in the data? If so, then its performance on new data may suffer because it has overspecialized. This is a bit like an overeager botanist who cannot recognize trees because they have a different number of leaves than he has every seen before. It is precisely this trade-off that leads to so many failures in the application of neural nets. The way that neural nets are trained (normally based on the error back-propagation algorithm) generally makes it difficult to avoid over-or under-specialization. Statistical Learning Theory and associated algorithms typically control this trade-off better.
Below are some references that address Statistical Learning Theory (the management of learning trade-offs) and Kernel Methods (the algorithms). The much celebrated Support Vector Machine approach is the best known application of kernel methods. In addition to the books that I have listed are a number of collections of papers at the Web site which are excellent.
I recommend starting by visiting the web site for the MIT graduate course in the Brain and Cognitive Sciences department on Statistical Learning Theory and Applications (9.520). http://www.mit.edu/~9.520/ The course is taught by seminal thinkers in the area and the handouts and syllabus are of the absolute highest quality.
John Shawe-Taylor & Nello Cristianini
Kernel Methods for Pattern Analysis
Cambridge University Press, 2004
This book is an excellent introduction with many details and references. Another great place to start.
N. Cristianini and J. Shawe-Taylor
An Introduction to Support Vector Machines (and other kernel-based learning methods)
Cambridge University Press, 2000
http://www.support-vector.net/This is the predecessor to Kernel Methods for Pattern Analysis ; It is more focused on SVMs but clear and useful in laying the foundation for understanding kernel methods more generally.
B. Scholkopf and A. J. Smola
Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond
MIT Press, 2002
http://www.amazon.com/Learning-Kernels-Regularization-Optimization-Computation/dp/0262194759This book is a deeper introduction with many excellent discussions regarding kernel design. Highly recommended.
And lest you have the impression that Deep Learning has crowded out all of the new work in kernel methods I recommend a very interesting recent (12/2019) article:
Divyansh Agarwal and Nancy R Zhang
Semblance: An empirical similarity kernel on probability spaces
Sci Adv. 2019 Dec 4;5(12):eaau9630. doi: 10.1126/sciadv.aau9630. eCollection 2019 Dec.
Additional General Background on Pattern Analysis
I do not recommend any of the books in this section unless you either wish to dive deep or you have masochistic tendencies. But they are additional good general introductions with twists that make them of interest.
J. Hertz, A. Krogh, and R.G. Palmer
Introduction to the Theory of Neural Computation
Westview Press; New Ed edition (January 1, 1991)
https://www.amazon.com/Introduction-Computation-Institute-Sciences-Complexity/dp/0201515601This is a view of neural network methods based on statistical mechanics. This book is interesting and very refreshing for those tired of poorly formulated biological analogies and wondering if another paradigm could motivate investigation. It is particularly good for the physics majors in the crowd.
B. D. Ripley
Pattern Recognition and Neural Networks
(Cambridge University Press, 2008)
https://www.amazon.com/gp/product/0521717701This book is a very complementary to Bishop's book listed above. It covers much the same material, but with a more rigorous statistical foundation and with very comprehensive references. He also is not shy about his opinions on research directions.
V.S. Cherkasski and F. Mulier
Learning from Data: Concepts, Theory, and Methods, 2nd Edition
Wiley-IEEE Press; 2nd edition, 2007
https://www.amazon.com/Learning-Data-Concepts-Theory-Methods/dp/0471681822Another good introduction (although I have not seen this edition.) Occasionally, I refer to the first edition of this book to supplement other sources.
Deeper Pattern Recognition General References
These references dive much deeper than the references listed above. They are only recommended if you wanted to see what the mathematical foundation of learning looks like. I have not listed many other references which are valuable, especially the books and papers by Vladimir Vapnik, which are brilliant but a bit opaque. The papers below are excellent doorways to the research literature.
T. Poggio, R. Rifkin, S. Mukherjee, and P. Niyogi
General Conditions for Predictivity in Learning Theory
Nature 428 (2004): 419-422.This is an excellent paper that explains the concept of stability as applied to learning in a clear compact exposition. Worth reading.
C. Tomasi
Past performance and future results
Nature 428 (2004): 378A comment on the previous paper that reinforces some important questions regarding small samples and stability.
F. Cucker, and S. Smale.
On The Mathematical Foundations of Learning. Bulletin of the American Mathematical Society 39, no. 1 (2002).
Learning theory for mathematicians. Excellent.
T. Poggio and S. Smale.
The Mathematics of Learning: Dealing with Data
Notices of the American Mathematical Society (AMS), Vol. 50, No. 5, 537-544, 2003.Deep and delightful. A bit more readable than Cucker and Smale.
S. Boucheron, O. Bousquet, and G. Lugosi
Theory of Classification: A Survey of Recent Advances.
ESAIM: Probability and Statistics 9 (2005): 323-375.S. Boucheron, O. Bousquet, and G. Lugosi
Introduction to Statistical Learning Theory.
In Advanced Lectures on Machine Learning. Lecture Notes in Artificial Intelligence 3176. Edited by O. Bousquet, U. Von Luxburg, and G. Ratsch. Heidelberg, Germany: Springer, 2004, pp. 169-207.Both of the above papers are excellent surveys of statistical learning theory. The second is easier to read. Both may be a bit dated now.
L. Devroye, L. Gyorfi, and G. Lugosi
A Probabilistic Theory of Pattern Recognition, Corrected Edition
(Springer, 1997)
https://www.amazon.com/Probabilistic-Recognition-Stochastic-Modelling-Probability/dp/0387946187A deep read into the 2-class pattern classification problem. Worth looking at after you think you know what is going on. Highly theoretical and engaging if you like such things.
Bayesian Methods / Causality / Belief Networks
I have mixed feelings about Bayesian methods. (That's a pun, by the way!)
Andrew Gelman, John B Carlin, Hal S Stern, David B Dunson and Donald B Rubin
Bayesian Data Analysis, 3rd Edition
(Chapman and Hall/CRC, 2013)
https://www.amazon.com/Bayesian-Analysis-Chapman-Statistical-Science/dp/1439840954The leading text on the Bayesian approach. Very thorough and pragmatic.
David J. C. MacKay
Information Theory, Inference, and Learning Algorithms
Cambridge University Press, 2003
http://www.amazon.com/Information-Theory-Inference-Learning-Algorithms/dp/0521642981MacKay's book is remarkable - a mix of probability theory, information theory, coding, some statistical physics, and some pattern recognition algorithms. This unusual combination of topics gives rise to some idiosyncratic presentations which often provoke new insights. It has a Bayesian flavor and provides some introduction to Bayesian inference and belief networks.
Judea Pearl
Causality: Models, Reasoning and Inference, 2nd Edition
(Cambridge University Press, 2009)
https://www.amazon.com/Causality-Reasoning-Inference-Judea-Pearl/dp/052189560X/A masterpiece by Pearl that supersedes his earlier work on graphical models. Before reading this, first read the next book.
Judea Pearl and Dana Mackenzie
The Book of Why: The New Science of Cause and Effect
(Basic Books, 2018)
https://www.amazon.com/Causality-Reasoning-Inference-Judea-Pearl/dp/052189560X/Easier to get into than Pearl's Causality and a very enjoyable read.
Stephen L Morgan and Christopher Winship
Counterfactuals and Causal Inference: Methods And Principles For Social Research, 2nd Edition
(Cambridge University Press, 2014)
https://www.amazon.com/Counterfactuals-Causal-Inference-Principles-Analytical/dp/1107694167/Very much more geared to direct application to research problems than Pearl's books. A bit dry but worthwhile.
M. I. Jordan (editor)
Learning in Graphical Models
(M.I.T. Press, 1999)
https://www.amazon.com/Learning-Graphical-Adaptive-Computation-Machine/dp/0262600323This is the source that taught me about belief networks. This is a collection of papers, four of which are tutorial, including Heckerman's well known tutorial.
Daphne Koller and Nir Friedman
Probabilistic Graphical Models: Principles and Techniques
(M.I.T. Press, 1999)
https://www.amazon.com/gp/product/0262013193I have not seen this book but it appears to be excellent and is on my wish list.
Formal Linguistics
It is easy to get lost in the maze of literature and schools of thought in formal linguistics. The mainstream of generative grammar stems from the brilliant contributions of Noam Chomsky at MIT. There have been significant breaks from this mainstream. The core controversies revolve around whether syntax should play the central role it does in formal linguistics and whether the transformational mechanisms developed by Chomsky and others are necessary or psychologically real.
Recently, the mainstream has been focused on a retrenchment called the "minimalist program." This is an attempt to reduce the transformational structure (that is, the correspondence between deep structure and surface structure) to a set of principles that govern core linguistic phenomena across all languages.
Like many students of linguistics, I had originally learned something about transformational grammar from one of the books of Andrew Radford, in my case, his book Transformational Syntax , Cambridge University Press, 1981. When I wanted to update some of my background I turned to Radford's Minimalist Syntax , Cambridge University Press, 2004. This is an excellent book, but I found myself increasingly at odds with its analysis.
I ended up rejecting the transformational approach entirely. The best thinking about alternative approaches that I have found is from Ray Jackendoff, one of Chomsky's students. A "must read" book on linguistics and cognitive science is:
Ray Jackendoff
Foundations of Language: Brain, Meaning, Grammar, Evolution
(Oxford University Press, 2003)
http://www.amazon.com/Foundations-Language-Meaning-Grammar-Evolution/dp/0199264376/In fact, if you were to read only one book this year, I would recommend it to be this one. Certainly, one of the best books I have ever read.
Other books from Jackendoff that I strongly recommend that pertain to cognitive structures (semantics) are:
Semantic Interpretation in Generative Grammar, MIT Press, 1972
Semantics and Cognition, MIT Press, 1983
Semantic Structures, MIT Press, 1990
Language, Consciousness, Culture: Essays on Mental Structure, MIT Press, 2007
Meaning and the Lexicon: The Parallel Architecture 1975-2010, Oxford University Press, 2010
One of the most interesting books on syntax is:
Ray Jackendoff and Peter Culicover
Simpler Syntax
(Oxford University Press, 2005)
http://www.amazon.com/Simpler-Syntax-Peter-W-Culicover/dp/0199271097
The Simpler Syntax hypothesis is that syntactic structure is only as complex as is required to form the connection between morphology (sounds, text forms) and cognitive structures (meaning). This does not mean that syntax is simple - only that the central position of syntax and the highly elaborated transformations of mainstream generative grammar have somehow diverged from reality. Simpler Syntax (like some other similar approaches) continues to be generative but rejects transformations and most of what would constitute a deep structure (except for a mechanism which handles the mapping of grammatical function).
The nature of Simpler Syntax "rules" is more akin to constraints - one set of constraints govern constituents, the other word order. And, the division between grammar and lexicon is broken down - lexical material is in a continuum from words to idioms and other constructions to general rules - all of which are connections between morphology, syntax, and meaning.
As for the structure of English, there is a remarkable descriptive grammar that has supplanted earlier works (such as Quirk, et al.) that weighs in (literally) at 1860 pages and 5.6 pounds:
Huddleston, RD and Pullum, GK
The Cambridge Grammar of the English Language
(Cambridge University Press, 2003)
http://www.amazon.com/Cambridge-Grammar-English-Language/dp/0521431468/
A summary of CGEL (as it is known) by the same authors is a text which can also be used as a reference:
Huddleston, RD and Pullum, GK
A Student's Introduction to English Grammar
Cambridge University Press, 2005
This book follows much of the structure of CGEL and I usually consult it first before diving into the trenches with CGEL.
Sample chapters (1 and 2) of CGEL are available here: http://www.cambridge.org/uk/linguistics/cgel/sample.htm
I recommend reading Chapter 2 as an intro to their style of exposition and the structure of English.
I also recommend Peter Culicover's review of CGEL. (Culicover is the co-author of Simpler Syntax ). The review is available here: http://www.cogsci.msu.edu/DSS/2005-2006/Culicover/CGEL%20Review.pdf
A complementary view to Jackendoff is in the work of Pustejovsky. I recommend:
Pustejovsky, James
The Generative Lexicon
(MIT Press, 1998)
http://www.amazon.com/Generative-Lexicon-Language-Speech-Communication/dp/0262661403Although primarily focused on nouns, this book describes the combinatory nature of meaning.
Finally, I have thoroughly enjoyed a number of other perspectives. A favorite is by George Lakoff (who was on the other side of an acrimonious period in linguistic development from Jackendoff, still known as the "linguistic wars.")
Lakoff, George
Women, Fire, and Dangerous Things. **** What Categories Reveal about the Mind ****.
(University of Chicago Press, 1990)
http://www.amazon.com/Women-Dangerous-Things-George-Lakoff/dp/0226468046/Lakoff also wrote Metaphors We Live By (with Mark Johnson) and has contributed at the intersection of linguistics and cognitive science. He is no stranger to controversy and I find him interesting and sometimes convincing.
A few more abbreviated references, all with the highest recommendation:
- Sag, Wasow and Bender, Syntactic Theory, 2nd Edition
- Boas and Sag, Sign-Based Construction Grammar
- Ginzburg and Sag, Interrogative Investigations: The Form, Meaning, and Use of English Interrogatives
- Goldberg, Constructions: A Construction Grammar Approach to Argument Structure
- Goldburg, Constructions at Work: The Nature of Generalization in Language
- Lieber, Morphology and Lexical Semantics
- Wechsler, Word Meaning and Syntax: Approaches to the Interface
- Heim and Kratzer, Semantics in Generative Grammar
The books that are listed immediately above have probably had the most lasting influence on my own research and development activities. For the largest part I find Sign-Based Construction Grammar to be the most compelling linguistic theory both from the view of explanatory power of (English) language phenomena and as a framework for developing deep grammars for computerized language understanding and generation.
Computational Linguistics
Formal and statistical approaches to machine understanding have wide and varied literatures. Strong opinions about the efficacy of different approaches seem to be the norm; I believe an eclectic approach is best and the best way to start is to survey a large number of techniques and implemented systems.
Formal parsing approaches have a long history. While it is logical to assume that a formal linguistic training would be a great preparation, an oft repeated quip is that every time a computational linguistics project hires a linguist, their accuracy drops. Still, I think that to the extent that a linguistic phenomena is understood, that formal methods should be used. Use statistical methods for less well understood phenomena.
The statistical approach to language understanding spans a huge array of attacks on NLP problems at different levels of analysis ranging from morphology, tagging, probabilistic parsing, and more.
A very good introduction to computational linguistics is:
D. Jurafsky and J. Martin
SPEECH and LANGUAGE PROCESSING
An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition
(Prentice Hall, 2008, Second Edition)I had a chance to read some of the revisions from the first edition. While I do not always agree on their selection of methods to illustrate or the trade-offs that they advocate, I do think that the book is an excellent survey.
E. Charniak
Statistical Language Learning
(M.I.T. Press, 1996)
http://www.amazon.com/Statistical-Language-Learning-Speech-Communication/dp/0262531410/This is a very clear and concise (short) introduction to statistical linguistics and a good start for deeper investigations. It discusses probabilistic chart parsing, hidden Markov models, and word clustering without getting caught up in the details. I think it is one of the best books to start with in statistical linguistics because it motivates deeper thinking extremely well. Also worth visiting Charniak's web page at Brown.edu.
C. Manning and H. Schuetze
Foundations of Statistical Natural Language Processing
MIT Press, 1999
http://www.amazon.com/Foundations-Statistical-Natural-Language-Processing/dp/0262133601An excellent introduction with a bit more elementary material and support. Probably eclipsed now by Jurafsky and Martin.
Going beyond these introductions requires expeditions into the literature and various resources. It is more difficult to provide specific guidance because the span of approaches described in the literature is so broad. Some of the most important threads are for patterned relation extraction and for predicate-argument structure matching.
The most widely used lexical resource is WordNet: http://wordnet.princeton.edu/ WordNet is a very large sense enumerative lexicon with a very broad coverage of English. WordNet related publications are available at the site. In addition, an (early) collection of papers was assembled and published:
C. Fellbaum (Editor) and G. Miller (Preface)
Wordnet: An Electronic Lexical Database
(M.I.T. Press, 1998)
http://www.amazon.com/WordNet-Electronic-Database-Language-Communication/dp/026206197X
Other resources include VerbNet, FrameNet, PropBank, and NomBank. All can be found easily on the Web with an abundance of associated papers.
One important direction is the induction of ontologies and lexicons from corpuses. This is closely related to information extraction from text.
Description Logics, OWL, and the Semantic Web
There are different conceptions of what should constitute a better "relationship" between humans and machines. One family of the articulations of these conceptions is the W3C Semantic Web. The Semantic Web is often attributed to Sir Tim Berners-Lee.
Berners-Lee, Tim; James Hendler and Ora Lassila
The Semantic Web. Scientific American Magazine. (May 17, 2001).
The W3C maintains a large number of resources that may be accessed here: http://www.w3.org/2001/sw/
Much of the effort of the Semantic Web development community is not without controversy. This exists at a variety of levels:
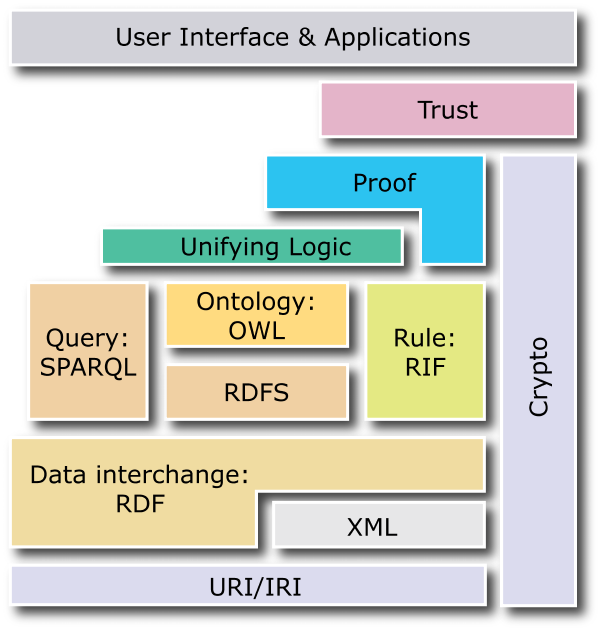
What should be the goals of the Semantic Web? Indeed, what is the Semantic Web?
What should the architecture of a Semantic Web look like? Is it like the "layer cake" of services that is so often reproduced?
What is the relative role of representation vs. inference? This is a big and deep question. We can, for example,
a. Store many pieces of data (say, triples) and retrieve using queries that match patterns (written in say, SPARQL);
b. Use a rule-based formalism to recursively compute answer sets; and
c. Use a Description Logic formalism for representing knowledge and computing implicit relationships (classification, transitive roles, and propagated roles).
What is the form that Web pages and other Web-accessible resources should encode self-descriptive metadata and data?
How should Semantic Web services be packaged and deployed? What security (encryption and trust) services should be used?
How does the Semantic Web relate to other semantic technologies including NLP, other forms of knowledge representation and reasoning, and knowledge visualization?
(I could go on.)
To listen to many Semantic Web advocates (including companies) the Semantic Web is almost equivalent to RDF(S) and SPARQL. In fact, RDF and SPARQL are interesting and useful, no doubt. But they are at best a partial solution to some knowledge representation problems and no solution at all to the most interesting problems.
RDF is a fine data interchange format. Beyond that, large sets of RDF triples are incredibly hard to manage efficiently and are disjoint from human understanding.
OWL is derived from decades of research in Description Logics. Description Logic engines enable the construction of many types of intelligent software agents to act on behalf of people. The most important agent behaviors are automatic classification of knowledge (particularly incrementally learned), translation of one organization of knowledge to another organization, and negotiation of protocols and services provided by different programs or data sources. A core enabling operation of many agents is the ability to create semantic metadata of documents (and other media) and combine knowledge from that metadata in ways that are meaningful to automated processes. For this to happen, ontologies will play a key role as a source of precisely defined and related terms (vocabulary) that can be shared across applications (and humans). DL technology formalizes ontology construction and use by providing a decidable fragment of First Order Logic (FOL). This formality and regularity enables machine understanding for the support of agent-agent communication, semantic-based searches, and provide richer service descriptions that can be interpreted by intelligent agents.
Rule formalisms can complement both RDF querying (using SPARQL) and description logic reasoning. But no single rule formalism can capture all of the kinds of reasoning that different common problems require. Various flavors of Datalog, constraint systems, SAT solvers, and of course Prolog are but a small sample.
And this is to say nothing of pattern discovery and machine learning algorithms which invariably would require data to be represented in forms quite different from RDF.
Finally, the three species of OWL version 1 were not found to be very useful. OWL Full is first order logic and requires powerful but slow theorem proving techniques and is, of course, not decidable. The other two species were impoverished in their ability to reason about relationships between concepts, among other deficiencies.
OWL version 2 remedies most of these problems. However, there is as yet no practical implementation of SROIQ, the particular variant of logic that underlies the full OWL V2. As a consequence, several fragments (or "profiles") of OWL V2 have been defined, the most important being EL++.
The Description Logic home page is located at: http://dl.kr.org/
Information on OWL 2 can be found at these links:
http://www.w3.org/2007/OWL/wiki/Primer
http://www.w3.org/TR/owl2-syntax/
http://www.w3.org/TR/owl2-semantics/
http://www.w3.org/TR/owl2-profiles/
Other papers that describe Description Logic technology that are good starting places are the following.
Franz Baader, Ian Horrocks, and Ulrike Sattler. Description Logics. In Frank van Harmelen, Vladimir Lifschitz, and Bruce Porter, editors, Handbook of Knowledge Representation. Elsevier, 2007. .pdf
Ian Horrocks, Oliver Kutz, and Ulrike Sattler. The Even More Irresistible _ SROIQ . In _Proc. of the 10th Int. Conf. on Principles of Knowledge Representation and Reasoning (KR 2006), pages 57-67. AAAI Press, 2006. .pdf
Boris Motik, Rob Shearer, and Ian Horrocks. A Hypertableau Calculus for _ SHIQ . In _Proc. of the 2007 Description Logic Workshop (DL 2007), volume 250 of CEUR (http://ceur-ws.org/), 2007. .pdf
Boris Motik, Rob Shearer, and Ian Horrocks. Optimized Reasoning in Description Logics using Hypertableaux. In Proc. of the 21st Int. Conf. on Automated Deduction (CADE-21), volume 4603 of Lecture Notes in Artificial Intelligence, pages 67-83. Springer, 2007. .pdf]
Dmitry Tsarkov, Ian Horrocks, and Peter F. Patel-Schneider. Optimising Terminological Reasoning for Expressive Description Logics. J. of Automated Reasoning, 2007. To appear. .pdf
Boris Motik, Rob Shearer, and Ian Horrocks. Optimizing the Nominal Introduction Rule in (Hyper)Tableau Calculi. In Proc. of the 2008 Description Logic Workshop (DL 2008), CEUR (http://ceur-ws.org/), 2008. .pdf
Franz Baader, Sebastian Brandt, and Carsten Lutz. Pushing the EL Envelope. In Proc. of the 19th Joint Int. Conf. on Artificial Intelligence (IJCAI 2005), 2005.
Franz Baader, Sebastian Brandt, and Carsten Lutz. Pushing the EL Envelope Further. In Proc. of the Washington DC workshop on OWL: Experiences and Directions (OWLED08DC), 2008.
Matthew Horridge, Nick Drummond, John Goodwin, Alan Rector, Robert Stevens, Hai H. Wang. The Manchester OWL Syntax. OWL Experiences and Directions Workshop, 2006.
Information on RDF and SPARQL is available at the W3C link that I provided above.
Datalog implementation usually is based on a query-rewriting technique called "magic sets." SQL3 incorporates recursive queries using Datalog-based ideas.
Ontology development
The structure, richness, and diversity of relationships that are typically expressed in an ontology are formalized in several ways. First, the language for the expression of those relationships is made rigorous. Differences in types of relationships are made explicit - for example, "X is a part of Y" may mean that X is a component (as in the example above), an ingredient (as in flour in a cake), a member (as in a person in a club), or other partonomic type.
Second, different qualifications on what may be expressed are formalized. For example, you may wish to say that "Joe has 3 daughters" without necessarily listing all (or any) of the daughters explicitly.
Third, we distinguish between those assertions that are both necessary and sufficient to fully define a relationship and those assertions which are only necessary. This corresponds to those things, which may be defined exactly, and those, which cannot and must have some additional qualitative verification.
Ontologies are formalized and exist because they enable knowledge to be redacted in ways that are more expressive or more natural for understanding than other formalisms such as relational datasets or logic-based rules. Ontologies exist and are in development for many domains. In fact, though, the power of an ontology is typically unlocked by some automatic reasoning engine based on a Description Logic.
Two papers related to the development of ontologies that are useful references are the following:
Natalya F. Noy and Deborah L. McGuinness
Ontology Development 101: A Guide to Creating Your First Ontology
http://protege.stanford.edu/publications/ontology_development/ontology101.pdf
Paul Buitelaar, Philipp Cimiano, Marko Grobelnik, Michael Sintek
Ontology Learning from Text
http://www.aifb.uni-karlsruhe.de/WBS/pci/OL_Tutorial_ECML_PKDD_05/ECML-OntologyLearningTutorial-20050923-2.pdf