Active Learning
Originally published on Tue, 05/07/2013 - 16:35
Active Learning is a strategy for efficiently using existing knowledge to form on-demand predictive judgments while guiding further experimentation. Active learning can be implemented using a variety of techniques and algorithms. This chapter addresses some of the most important techniques as implemented in Active Knowledge Studio.
A traditional dichotomy in the machine learning field has existed between techniques for unsupervised learning and supervised learning. In unsupervised learning, we seek to discover patterns or structure through algorithms that automatically group data points into clusters or by transforming the data to discover lower dimension representations that are good approximations or through other manipulations that provide function or summaries of the latent relationships that seem to appear within the sample data. Unsupervised learning is often accompanied with various visualization techniques to provide exploratory data analysis environments.
Supervised learning is the creation of a predictive model that when given an example will compute an output (often called a label). The output most often is the class that the example falls into and often there are only two classes (yes and no). The predictive model is trained on a set of examples where the labels are already known.
There are many techniques for supervised learning. Many of the techniques are variants of artificial neural nets (ANN). More recent techniques are based on what are known as “margin methods.” These include Support Vector Machines (SVMs), various regularization methods including Regularized Least Squares Classification (RLSC), and methods for improving the performance of weak classifiers such as bagging and boosting.
The dichotomy between unsupervised and supervised learning is not realistic for many problem settings. For example, combinatory chemistry can produce a huge number of candidate compounds that may have some desired property. How do we best structure experiments on batches (subsets) of the candidates to most efficiently explore the possibilities? Techniques for Active Learning address this problem setting.
Active Learning exploits labeled and unlabeled examples. Normally, active learning starts with a set of examples where none have labels. Some initial batch is picked at random or based upon some reasonable criteria, usually the insights of the researcher. Experiments are performed to determine the labels of the examples in that batch. A margin method is used to create an initial classifier. This creates the situation illustrated in the figure below.
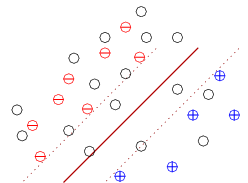
Positive, negative, and unlabeled examples
The most interesting unlabeled examples are those near the margin. These examples will form the majority of the examples selected for the next batch of experiments. Some examples are typically picked away from the margin to explore more of the possible classification space until the researcher believes that the classifier is reliably predictive. In addition, unlabeled examples that are far away from other examples may be outliers indicative of other mechanisms or of problems with data collection.
After a number of rounds where the experimental results largely match the predicted results, the remaining unlabeled examples are conditionally labeled and further experimentation is deemed unnecessary.
A variant of Active Learning focuses on exceptions. Those examples that are incorrectly labeled are investigated. They may be most useful in the determination of additional features that could be collected to create a better basis for calculation. Or, they may be incorrectly labeled as a result of experimental or transcription errors.